InnoDB存储引擎的数据页结构 数据处理与存储支持服务详解
引言
InnoDB是MySQL最核心、应用最广泛的存储引擎,以其出色的ACID事务支持、行级锁定、崩溃恢复能力和外键约束而著称。所有这些高级功能的实现,都离不开其底层精心设计的数据存储单元——数据页(Data Page)。本文将深入剖析InnoDB的数据页结构,并阐述它如何为上层的数据处理与存储支持服务奠定坚实的基础。
一、InnoDB数据页概览
在InnoDB中,所有数据(包括表数据、索引数据)都被逻辑地存储在称为“表空间”的文件中,而物理存储和管理的基本单位就是“页”(Page),默认大小为16KB。页是磁盘与内存之间交互的最小单元。当需要读取或修改数据时,InnoDB会将整个页加载到内存的缓冲池(Buffer Pool)中,操作完成后再以页为单位刷回磁盘。这种设计极大地优化了I/O效率。
二、数据页的物理结构
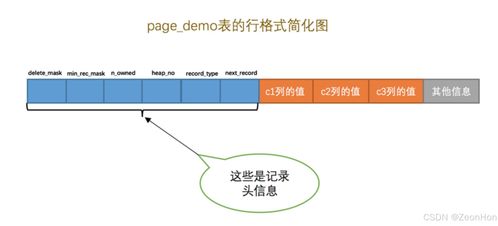
一个标准的16KB InnoDB数据页由七个主要部分组成,其结构如下图所示(此处为文字描述):
| 部分 | 大小 | 描述 |
| :--- | :--- | :--- |
| File Header(文件头) | 38字节 | 包含页的元信息,如页号、前后页指针(用于构成双向链表)、页类型等。 |
| Page Header(页头) | 56字节 | 包含页状态信息,如槽位数量、堆中记录数量、最后插入位置等。 |
| Infimum + Supremum Records(最小&最大记录) | 26字节 | 两个虚拟的系统记录,定义了页中记录的边界。Infimum比任何记录都小,Supremum比任何记录都大。 |
| User Records(用户记录) | 动态 | 实际存储行记录和索引键值的地方,记录以单链表或(对于紧凑行格式)单链表方式连接。 |
| Free Space(空闲空间) | 动态 | 页中尚未使用的空间,新的记录会首先插入到这里。 |
| Page Directory(页目录) | 动态 | 存放“槽”(Slots),每个槽指向页内一组记录中的最大那条记录,实现页内记录的二分查找。 |
| File Trailer(文件尾) | 8字节 | 包含一个校验和(Checksum),用于页数据刷盘时校验页的完整性,防止部分写(partial write)问题。 |
三、核心组件详解与数据处理支持
- 链表结构与顺序访问
- Fil Header中的前后页指针:将所有同类型的页(如属于同一个B+树索引的叶子节点页)链接成一个双向链表。这支持了高效的范围扫描(Range Scan),例如执行
WHERE id BETWEEN 10 AND 100时,可以快速定位到起始页,然后沿着链表顺序读取后续页。
- User Records中的记录指针:用户记录通过
next_record指针连接成一个单向链表。这个链表默认按照主键顺序(对于索引组织表)或插入顺序连接,使得全页扫描和顺序插入变得高效。
- 页目录与高效查找
- Page Directory是InnoDB页内查找的“索引”。它不会为每条记录都建立槽,而是将页内的所有记录(包括Infimum和Supremum)分成若干组,每组最后一条记录的地址被存储在槽中。槽本身在页目录中按顺序存储。
- 查找过程:当需要根据主键或唯一键在页内定位一条记录时,InnoDB首先对页目录进行二分查找,快速定位到记录所在的分组,然后在该分组内通过记录链表进行小范围的线性查找。这大大提升了页内数据检索的速度,将时间复杂度从O(n)降低到接近O(log n)。
3. 记录格式与存储优化
InnoDB的行记录格式(如COMPACT、DYNAMIC)直接影响User Records的存储方式。以DYNAMIC格式为例:
- 对于变长字段(如VARCHAR),只存储实际长度和指向溢出页的指针(当数据超出行最大限制时),极大地节省了页内空间。
- 记录头信息(Record Header)存储了事务ID、回滚指针、下一记录指针等关键信息,直接支持了MVCC(多版本并发控制)和事务回滚。
四、为存储支持服务提供基石
- 事务支持(ACID)
- 原子性与持久性:页是重做日志(Redo Log)和刷脏(Flush)操作的基本单位。事务的修改先在内存页中进行,并生成重做日志。File Trailer的校验和确保了页写入磁盘的原子性,结合日志,共同保障了事务的持久化和崩溃恢复能力。
- 隔离性:记录头中的事务ID和回滚指针是实现MVCC的关键。通过它们,不同的事务可以访问到符合其隔离级别要求的数据版本,从而实现了非锁定的一致性读和行级锁。
2. 索引组织
InnoDB表是索引组织表(IOT),其主键索引的叶子节点页直接存储完整的行数据。数据页的结构完美适配了B+树索引:
- 页作为B+树的节点,File Header中的指针维护了树的层次结构。
- 在索引页(非叶子节点)中,User Records存储的是键值和指向子页的指针。
- 高效的数据页内查找(页目录)使得从根节点到叶子节点的搜索路径非常快速。
- 空间管理与并发控制
- Page Header跟踪了空闲空间、记录数量等信息,优化了新记录的插入位置(如顺序插入会尝试填充最后插入位置之后的空间)。
- 行级锁实际上是通过对内存中数据页的特定记录加锁来实现的。页结构使得锁管理器能够精确定位到需要加锁的记录。
五、
InnoDB数据页远不止是一个简单的磁盘块。它是一个高度结构化、功能丰富的微型数据库单元,集数据存储、快速检索、事务信息维护和空间管理于一体。从File Header到File Trailer,每一个字节的设计都旨在高效地支撑上层的复杂服务:无论是执行一条简单的SELECT查询,还是处理一个包含多语句的分布式事务,其底层都在与无数个这样的数据页进行交互。理解数据页的结构,是深入理解MySQL InnoDB存储引擎高性能、高可靠性奥秘的关键所在,也为数据库性能调优(如合理设计主键、避免行溢出、理解页分裂等)提供了根本性的视角。
如若转载,请注明出处:http://www.zhaocebao.com/product/39.html
更新时间:2026-04-16 14:37:17